Archive for the ‘Events’ Category
 Making Internal Activity Streams like Tibbr Valuable
Making Internal Activity Streams like Tibbr Valuable
Rob Koplowitz of Forrester recently posted, Why Tibbr Matters. He provided some examples of where an activity stream across a network like Tibbr could add value, and some examples where it couldn’t. I responded with a comment and I wanted to elaborate on my comments here.
Activity streams tied to your company that are available through tools like Chatter, Yammer, and Tibbr have potential for adding value, but there’s some big barriers that must be overcome. In my experience, I’ve used email, Sharepoint and other other internal portals, and Yammer inside of a corporate setting, and there’s two simple objectives that these tools should have, at a minimum:
- Moving information from the privileged few to a broader audience.
- Making new information available that previously wasn’t.
On the first item, a challenge that probably every organization has is getting the information to the right people. The information exists, but it only spreads through word of mouth or to people that the information holders think need to be aware of it. The twitter model is the right approach for addressing this, by allowing people to follow people or topics of interest (either via saved keyword searches or hashtags), rather than having to wait until it is explicitly sent to them. In order for this model to work, however, all information must be public. As soon as private, directed messages come into play, that information is now hidden. I don’t see this as the bigger of the two challenges, however, as at least the information exists, it’s just not getting everywhere it needs to go.
The second item is the greater challenge. If there is information that simply isn’t being communicated, there is no tool that is going to magically make that information appear. The more information sources you have participating in the network, the greater potential you have for getting value out of that network. Why does everyone join Facebook? It’s the network with the greatest participation, and therefore, the greatest potential value. There’s a catch-22 here, because you want participants to get value quickly, so they stay in the network, but once you get over the hurdle, the growth will come. So how do we do this?
In a corporate setting, the participants are not just your employees. The participants must include your systems. This is why Tibbr is potentially in a good spot. Tibco’s background is not in collaboration or social media, it is in system integration. Unfortunately, all of the web-based request/response systems over the past decade have gotten us away from the asynchronous, event-based system design of the past. Even SOA tends to imply a request-response paradigm in most people minds, meaning I have to know what to ask for in advance. Both our systems and our people need to expose items of interest without any preconceived notion of who might be interested. Yes, we need to be cautious about signal to noise ratio, but I don’t think that problem is any different than trying to manage redundancy in an application or service portfolio. As part of your deployment process, get a list of the events/messages that are available, categorize them, and manage them effectively. If the Twitterverse can quickly come up with accepted hashtags, why can’t we do the same inside our corporate worlds?
Since I’ve previously asked for this year to be the year of the event, let’s do so in a way that allows these events to feed into our internal activity streams and social networking tools, and start getting real value out of these technologies.
Make 2011 the Year of the Event
In this, my first blog post of 2011, I’d like to issue a challenge to the blogosphere to make 2011 the year of the event. There was no shortage of discussions about services in the 2000’s, let’s have the same type of focus and advances in event’s in the 2010’s.
How many of your systems are designed to issue event notifications to other systems when information is updated? In my own personal experience, this is not a common pattern. Instead, what I more frequently see is systems that always query a data source (even though it may be an expensive operation) because a change may have occurred, even though 99% of the time, the data hasn’t. Rather than optimizing the system to perform as well as possible for the majority of the requests by caching the information to optimize retrieval, the systems are designed to avoid showing stale data, which can have a significant performance impact when going back to the source(s) is an expensive operation.
With so much focus on web-based systems, many have settled into a request/response type of thinking, and haven’t embraced the nearly real-time world. I call it nearly real-time, because truly real-time is really an edge case. Yes, there are situations where real-time is really needed, but for most things, nearly real-time is good enough. In the request/response world, our thinking tends to be omni-directional. I need data from you, so I ask you for it, and you send me a response. If I don’t initiate the conversation, I hear nothing from you.
This thinking needs to broaden to where a dependency means that information exchanges are initiated in both directions. When the data is updated, an event is published, and dependent systems can choose to perform actions. In this model, a dependent system could keep an optimized copy of the information it needs, and create update processes based upon the receipt of the event. This could save lots of unnecessary communication and improve the performance of the systems.
This isn’t anything new. Scalable business systems in the pre-web days leveraged asynchronous communication extensively. User interface frameworks leveraged event-based communication extensively. It should be commonplace by now to look at a solution and inquire about the services it exposes and uses, but is it commonplace to ask about the events it creates or needs?
Unfortunately, there is still a big hurdle. There is no standard channel for publishing and receiving events. We have enterprise messaging systems, but access to those systems isn’t normally a part of the standard framework for an application. We need something incredibly simple, using tools that are readily available in big enterprise platforms as well as emerging development languages. Why can’t a system simply “follow” another system and tap into the event stream looking for appropriately tagged messages? Yes, there are delivery concerns in many situations, but don’t let a need for guaranteed delivery so overburden the ability to get on the bus that designers just forsake an event-based model completely. I’d much rather see a solution embrace events and do something different like using a Twitter-like system (or even Twitter itself, complete with its availability challenges) for event broadcast and reception, than to continue down the path of unnecessary queries back to a master and nightly jobs that push data around. Let’s make 2011 the year that kick-started the event based movement in our solutions.
Tibbr and Information in the Enterprise
Back in March of this year, I asked “Is Twitter the cloud bus?” While we haven’t quite gone there yet, Tibco has run with the idea of Twitter as an enterprise messaging bus and announced Tibbr. This is a positive step toward the enterprise figuring out how to leverage social computing technologies in the enterprise. While I think Tibco is on the right track with this, my pragmatist nature also sees that there’s a long way to go before these technologies achieve mainstream adoption.
The biggest challenge is creating the robust information pool. Today, the biggest complaint of newcomers to Twitter is finding information of value. It’s like walking into the largest social gathering you’ve ever seen and not knowing anyone. You can walk around and see if you overhear someone discussing something interesting, but that can be a daunting task. Luckily, however, there are millions of topics being discussed at any given time, so with the help of a search engine or some trusted parties, you can easily begin to build the network. In the enterprise, it’s not quite so easy.
When looking at information sharing, here are two key questions to consider:
- Are new people receiving information that they would not otherwise have seen, and are they contributing back to the conversation?
- Are the conversation groups the same, but the information content improved in either its relevance, timeliness, quality, preservation, or robustness?
If the answer to both of those is “no”, then all you’ve done is create a new channel for an existing audience containing information that was already being shared between them. Your goals must be to enable one or more of the following:
- Getting existing information to/from new parties
- Getting new information to/from existing parties
- Delivering more robust/higher quality information to/from existing parties
- Delivering information in a more timely/appropriate manner to existing parties
- Making information more accessible (e.g. search friendly)
The challenge in achieving these goals via social networking tools begins with information sources. If you are an organization with 10,000 employees, only a small percentage of those employees will be early adopters. Strictly for illustrative purposes, let’s use IT department size as a reasonable guess to the number of early adopters. In reality, a lot of people IT will jump on it, as will a smaller percentage of employees outside of IT. A large IT department for a 10,000 person company would be 5%, so we’re looking at 500 people participating on the social network. Can you see the challenge? Are these 500 people merely going to extend the conversations they’re having with the same old people, or is the content going to meet the above goals?
Now comes along Tibbr, but does the inclusion of applications as sources of information improve anything? If anything, the way we’ve approached application architecture is even worse than dealing with people! Applications typically only share information when explicitly required by some other application. How many applications in your enterprise routinely post general events, without concern for who may be listening for them? Putting Tibbr or any other message bus in place is only going to be as valuable as the information that’s placed on the bus and most applications have been designed to keep information within its boundaries unless required.
So, to be successful, there’s really one key thing that has to happen:
Both people and applications must move from a “share when asked” mentality to a “share by default” mentality.
When I began this blog, I wasn’t directing the conversation at anyone in particular. Rather, I made the information available to anyone who may find it valuable. That’s the mentality we need in our organizations and the architecture we need in our applications. Events and messages can direct people to the appropriate gateway, with either direct access to the information, or instructions on how to obtain it if security is a concern. Today, all of that information is obscured at a minimum, and more likely locked down. Change your thinking and your architecture, and the stage is set for getting value from tools like Tibbr.
Oracle Business Activity Monitoring and Oracle Complex Event Processing
Full disclosure: I’m attending Oracle OpenWorld courtesy of Oracle.
I was late to this session as my panel preceeded it, and the questions continued for a good 30 minutes after the session ended. Thank you to all who attended, and the positive feedback was great.
The speaker went over the basics of Oracle’s CEP platform, introducing the query language they use for event streams (CQL). No surprises in terms of the approach, it looks like other CEP’s I’ve seen. They emphasized the role that Coherence plays in the scalability of the platform. I do like the use of Coherence as a common platform across all of their middleware products, it makes a lot of sense.
They went on to present a demo of CEP in action, where the CEP was processing location based events associated with emergency responders. One thing they didn’t call out is the need for some system to make the decision to actually publish events. In my opinion, this is one of the key things holding back adoption of things like CEP. The average app developer working on a web-based transactional system just doesn’t think about publishing events unless they have some concrete consumer of those events. Just as we may not know all consumers of a service, we may not know all consumers of events. Would the developer on this system really know to be publishing source locations associated with connectivity or message traffic in advance? Initially, we’ll need to simply leverage message flows that are already occurring, similar to an intrusion detection systems to extract information that should be events, but instead are embedded in some other message. This creates a need for standard headers and message bodies to allow the CEP engine to have something consistent to query against.
Consistent with my previous posts on CEP, it looks like great technology, but the definition of problems where it is best applied are still evolving and maturing.
Gartner EA: Context Delivery Architecture
Presenter: William Clark
I’m looking forward to this talk, as it’s a new area for me. I don’t remember who told me this, but the key to getting something out of a conference is go to sessions where you have the opportunity to learn something, and you’re interested in the subject. That’s why I’m avoiding sessions on establishing enterprise technology architects. I’ve been doing that for the past 5 years, so the chances are far less that I’m going to learn something new than in a session like this one, where it’s an emerging space and I know it’s something that is going to be more and more important in my work in the next few years. The only downside is I’m now on my fourth day in Orlando which is starting to surpass my tolerance limit for sitting and listening to presentations.
He’s started out by showing that the thing missing from the digital experience today is “me.” By me, he implies the context of why we’re doing the things that we’re doing, such as “where am I,” “what have I done,” “who are you talking to,” etc. He points out the importance of user experience in the success and failures of projects, especially now in the mobile space.
Some challenges he calls out with incorporating context into our systems:
- Blending of personal contexts and business contexts. For example, just think of how your personal calendar(s) may overlap with your business calendar.
- Managing Technical Contexts: What device are you using, what network are you connecting from, etc. and what are the associated technical capabilities available at that point?
- Context timing: The context is always in a state of flux. Do I try to predict near-term changes to the context, do I try to capture the current context, or do I leverage the near-past context (or even longer) in what is shown?
It’s always a sign of a good presentation when they anticipate questions an audience might ask. I was just about to write down a question asking him if he thinks that a marketplace for context delivery will show up, and he started talking about exactly that. This is a really interesting space, because there’s historical context that can be captured and saved, and there’s an expense associated with that, so it makes sense that the information broker market that currently selling marketing lists, etc. will expand to become on-demand context providers with B2B style integrations.
All in all, I see this space with parallels to the early days of business intelligence. The early adopters are out there, trying to figure out what the most valuable areas of “context” are. Unlike BI, there are so many technology changes going on that are introducing new paradigms, like location aware context with cellphones, there’s even more uncertainty. I asked a question wondering how long it will be before some “safe” areas have been established for companies to begin leveraging this, but his answer was that there are many dimensions contributing to that tipping point, so it’s very hard to make any predictions.
This was a good presentation. I think he gave a good sampling of the different data points that go into context, some of the challenges associated with it, and the technical dynamics driving it. It’s safe to say that we’re not at the point where we should be recommending significant investments in this, but we are at the point where we should be doing some early research to determine where we can leverage context in our solutions and subsequently make sound investment decisions.
Some recent podcasts
I wanted to call attention to four good podcasts that I listened to recently. The first is from IT Conversations and the Interviews with Innovators series hosted by Jon Udell. In this one, he speaks with Raymond Yee of UC Berkeley, discussing mashups. I especially liked to discussion about public events, and getting feeds from the local YMCA. I always wind up putting in all my kids games into iCal from their various sports teams, it would be great if I could simply subscribe from somewhere on the internet. Jon himself called out the emphasis on this in the podcast in his own blog.
The next two are both from Dana Gardner’s Briefings Direct series. The first was a panel discussion from his aptly-renamed Analyst’s Insight series (it used to be SOA Insights when I was able to participate, but even then, the topics were starting to go beyond SOA), that discussed the recent posts regarding SOA and WOA. It was an interesting listen, but I have to admit, for the first half of the conversation, I was reminded of my last post. Throughout the discussion, they kept implying that SOA was equivalent to adopting SOAP and WS-*, and then using that angle to compare it to “WOA” which they implied was the least common denominator of HTTP, along with either POX or REST. Many people have picked up on one comment which I believe was from Phil Wainewright, who said, “WOA is SOA that works.” Once again, I don’t think this was a fair characterization. First off, if we look at a company that is leveraging a SaaS provider like Salesforce.com, Salesforce.com is, at best, a service provider within their SOA. If the company is simply using the web-based front end, then Salesforce.com isn’t even a service provider in their SOA, it’s an application provider. Now, you can certainly argue that services from Amazon and Google are service providers, and that there’s some decent examples of small companies successfully leveraging these services, we’re still a far cry away from having an enterprise SOA that works, whichever technology you look at. So, I was a bit disappointed in this part of the discussion. The second half of the discussion got into the whole Microhoo arena, which wound up being much more interesting, in my opinion.
The second one from Dana was a sponsored podcast from HP, with Dana discussing their ISSM (Information Security Service Management) approach with Tari Schreider. The really interesting thing in this one was to hear about his concept of the 5 P’s, which was very familiar to me, because the first three were People, Policies, and Process (read this and this). The remaining two P’s were Products and Proof. I’ve stated that products are used to support the process, if needed, typically making it more efficient. Proof was a good addition, which is basically saying that you need a feedback loop to make sure everything is doing what you intended it to. I’ll have to keep this in mind in my future discussions.
The last one is again from IT Conversations, this time from the O’Reilly Open Source Conference Series. It is a “conversation” between Eben Moglen and Tim O’Reilly. If nothing else, it was entertaining, but I have to admit, I was left thinking, “What a jerk.” Now clearly, Eben isn’t a very smart individual, but just as he said that Richard Stallman would have come across as to ideological, he did the exact same thing. When asked to give specific recommendations on what to do, Eben didn’t provide any decent answer, instead he said, “Here’s your answer: you’ve got another 10 years to figure it out.”
March Events
Here are the SOA, BPM, and EA events coming up in March. If you want your events to be included, please send me the information at soaevents at biske dot com. I also try to include events that I receive in my normal email accounts as a result of all of the marketing lists I’m already on. For the most up to date list as well as the details and registration links, please consult my events page. This is just the beginning of the month summary that I post to keep it fresh in people’s minds.
- 3/3: ZapThink Practical SOA: Pharmaceutical and Health Care
- 3/4: Webinar: Implementing Information as a Service
- 3/6: Global 360/Corticon Seminar: Best Practices for Optimizing Business Processes
- 3/10 – 3/13: OMG / SOA Consortium Technical Meeting, Washington DC
- 3/10: Webinar: Telelogic Best Practices in EA and Business Process Analysis
- 3/11: BPM Round Table, Washington DC
- 3/12 – 3/14: ZapThink LZA Bootcamp, Sydney, Australia
- 3/13: Webinar: Information Integrity in SOA
- 3/16 – 3/20: DAMA International Symposium, San Diego, CA
- 3/18: ZapThink Practical SOA, Australia
- 3/18: Webinar: BDM with BPM and SOA
- 3/19: Webinar: Pega, 5 Principles for Success with Model-Driven Development
- 3/19: Webinar: AIIM Webinar: Records Retention
- 3/19: Webinar: What is Business Architecture and Why Has It Become So Important?
- 3/19: Webinar: Live Roundtable: SOA and Web 2.0
- 3/20: Webinar: Best Practices for Building BPM and SOA Centers of Excellence
- 3/24: Webinar: Telelogic Best Practices in EA and Business Process Analysis
- 3/25: ZapThink Practical SOA: Governance, Quality, and Management, New York, NY
- 3/26: Webinar: AIIM Webinar: Proactive eDiscovery
- 3/31 – 4/2: BPM Iberia – Lisbon
February Events
Here are the SOA, BPM, and EA events coming up in February. If you want your events to be included, please send me the information at soaevents at biske dot com. I also try to include events that I receive in my normal email accounts as a result of all of the marketing lists I’m already on. For the most up to date list as well as the details and registration links, please consult my events page. This is just the beginning of the month summary that I post to keep it fresh in people’s minds.
- 2/4 – 2/6: Gartner BPM Summit
- 2/5: ZapThink Practical SOA: Energy and Utilities
- 2/7 – 2/8: Forrester’s Enterprise Architecture Forum 2008
- 2/11: Web Services on Wall Street
- 2/13 – 2/15: ARIS ProcessWorld
- 2/13: ZapThink Webinar: Leverage Document Centric SOA for Competitive Advantage
- 2/19: Webinar: Integrated SOA Governance
- 2/25 – 2/28: BPTG’s Business Process Transformation – BPM Practitioner Course
- 2/25 – 2/27: Global Excellence Awards in BPM & BPM Technology Showcase
- 2/26 – 2/29: ZapThink LZA Bootcamp
More on Events
Ok, the events page is finally functional. I gave up on WordPress plugins, and am now leveraging an embedded (iframe) Google Calendar. A big thank you to Sandy Kemsley, as she already had a BPM calendar which I’m now leveraging and adding in SOA and EA events. I hope this helps people to find out the latest on SOA, EA, and BPM events.
Making events, EDA, CEP, and SOA interesting
I’m back from my vacation and have a few topics queued up for some blog entries. The first one that I wanted to cover was the topic of events and SOA. The relationship between EDA, CEP, and SOA is one that pops up on a regular basis, however, in my opinion, it still hasn’t reached a sustained level of interest. There was a big peak some time ago when Oracle and Gartner used the ill-fated moniker SOA 2.0 to represent the combination of SOA and EDA, but once the backlash died down, the discussion around events faded back into the background again. Thankfully, it hasn’t gone away completely. One of the more recent publications on the topic came from Rich Seeley with SearchWebServices.com in this article. He stated that, “The relationship of complex event processing (CEP) to service-oriented architecture (SOA) remains, in a word, complex.” Why is the case?
The article included quotes from Jason Bloomberg of ZapThink comparing EDA to SOA. While I usually agree with the ZapThink guys, I disagree with Jason’s quote that there is no particular reason to distinguish SOA from EDA. Jason points out that all service messages are essentially software events which “contain all the information you’d ever want about the behavior and state of your business.” At a technical level, there’s nothing wrong with Jason’s statement. Where there are differences, however, is in the intent of the message. A message associated with an interaction between a service consumer and a service provider is either a request for the provider to do something or a response from the provider back to that consumer. The fundamental difference, in my opinion, is that these messages are directed at a specific destination. While you can certainly intercept these messages and use them for other purposes (and I’d argue that doing for so for business intelligence analysis reasons is a good thing), there’s a risk involved in doing this because now there are unintended side effects. In contrast, events have no requirement to be directed at any particular destination, typically using a publish-subscribe approach for distribution.
Let me get back to the question of complexity. I will admit that discussions like paragraph above are part of the reason that people find EDA and CEP hard to grasp. Often times, discussion in the blogosphere will focus on areas of disagreement, losing sight of the areas of agreement. I’d argue that if you talked to Jason and myself on the relationship between SOA and EDA, 80% of what you’d hear would be consistent. So, just because Rich Seeley received a number of different takes on SOA, CEP, and EDA, doesn’t mean it’s complex.The right question we should be tackling is how to make events, EDA, and CEP more interesting, building on the natural relationship to SOA. As I’ve previously stated in my uptake of CEP post, I don’t think that most organizations are ready for CEP and EDA yet. The debates that are occurring in the blogosphere and press are being made by people that have a vested interest (typically vendors, but you could argue that niche analyst firms do as well) in creating “buzz” about the topic. As a corporate practitioner, I have no such vested interest except where it makes business sense for my employer. So, I need to ask the question on how to make CEP and EDA relevant (and interesting) to the business. The challenge with it, and why it was important that I wrote about my difference of opinion with Jason of ZapThink, is that events, on their own, don’t do anything. A service performs some function. It does something. The business can grasp this. An event is just a nugget of information. A collection of events presented to business stakeholders are not going to be very meaningful until you start doing something with them. As a comparison, let’s look at baseball. If you watch or listen to a baseball game, you’ll get a barrage of statistics. Are they useful? Some managers, like Tony LaRussa of my hometown St. Louis Cardinals, have always made extensive use of the data. Has it made him more successful? We’ll probably never know. We can certainly say that he’s been a successful manager, but can we tie it specifically to his use of event capture and analysis? There are probably other managers or baseball pundits that would argue that the cost of collection and analysis isn’t worth it.
The same thing holds true for EDA and CEP. There is a cost associated with the generation of events. There is a cost associated with the analysis of events. What’s missing is the benefit. To get this, we need to do analysis of the business and come up with suitable justification. For a domain such as risk analytics associated with securities trading, the justification is there. Complex analysis of the trading and news events occurring in real time can result in better timed market activities with millions of dollars in potential benefits. In other domains, it may not be as crystal clear. If an organization has a stated goal of better knowledge of their customers, it would seem that event capture and analysis could assist in this, but how do we quantify the potential benefits? Just as with SOA, I think a key to this is selecting an appropriate proof-of-concept and then pilot. Some event capture and analysis can be done without purchasing any new infrastructure. There’s nothing wrong with performing analysis on a week’s worth of data that takes another week to complete if the end result is valuable, business relevant information. As Jason suggests, you can use service messages as your starting point for analysis, so if you’ve got audit logs of them, you only then need an analysis engine. Every organization already has many of these, and I’m not talking about a BI system. I’m talking about employees. While we may not capture all of the correlations, most of us are pretty good at spotting trends. It’s simply a matter of having someone look at the information that’s already there. Guess what that activity is? It’s business analysis. Do the analysis, understand the business, create the business case, and go make things better.
External Events in Action
I received a press release in email from Xignite entitled “Partnership Delivers Financial Professionals Responsiveness, Collaboration Via Timely Earnings Data.” In this release Xignite announced their partnership with Wall Street Horizon, a provider of earnings event and calendar information to the investment industry. Xignite will redistribute Horizon’s earnings and events calendar content as part of its street-event driven series on-demand financial web service.
While I normally don’t try to be a recycler of press releases from vendors, as I’d much rather comment on things more directly associated with work as a practicing architect, I’d be very happy to see more and more of these types of releases. Why? In the past, I’ve talked about the importance of events, such as this post. One of the challenges, however, is that I don’t really feel that there are good sources of events, especially ones that come in from outside of the enterprise (although there are times that I think that outside sources are more likely that internal sources…). Here’s a press release that shows that external sources are appearing and through partnerships, trying to increase their audience. It would be great if some of the industry consortiums for specific verticals would develop some standards in the event space.
External consumers and providers
James McGovern, in his links entry for April 11th posted this comment in regards to my entry on what SOA adoption actually means:
“A measurement that would be interesting is to ask enterprises how many services do you have that are consumed outside of your enterprise. The numbers would be dramatically lower…”
As I thought about this, it became more and more interesting. First, I definitely agree that the number of services is going to be dramatically lower, unless your company is already a service provider (think ASP), in which case, then it should constitute the majority of your service portfolio. What about other verticals, however? Certainly supply chain interactions will involve external entities. Truth be told, there’s lot of potential for interactions with partner companies. How many companies outsource payroll processing to ADP or someone else? I’d venture a guess that there are probably areas for commodity services in every vertical. Over time, things that once were competitive differentiators become commodities. Once that happens, a marketplace opens up for commodity providers that focus on operational excellence and low cost, and the companies that prefer to focus on customer service get rid of their homegrown infrastructure and leverage the commodity provider. Guess what, when that happens, the potential now exists for service interactions. I recently presented some introductory information on service concepts and described business services as services that both ones that represent the primary business functions as well as ones that support the primary business such as HR, payroll, etc. Technology clearly plays a big role in both.
You may be thinking, “No arguments on what you said, but James asked about services consumed by outsiders, not provided by outsiders.” Quite true, but again, I’d be willing to bet that the vast majority of these B2B interactions will require bi-directional communications. It may be the case that 90% of the time, the partner acts in the service provider role, but odds are that some of that processing will require them having the ability to make service calls back to you. At a minimum, some form of events should be flowing back into your infrastructure. The more information flow can be a circle, rather than a one-way line, the greater the potential for leveraging emerging technologies like CEP for continued innovation. If the information only flows one way, you severely restrict your ability to innovate based on that information.
Aside:James also posted some musings on Open Source and the possibilities of it playing a role in commodity vertical applications yesterday. If that happened, there would certainly have potential implications. It probably wouldn’t take long for someone to create a hosted solution for these open source offerings, again creating the potential for service interactions between the two companies.
The end result of my thinking on this is that if your thinking on SOA is constrained to inside your firewall, it won’t be very long at all before you need to extend that thinking, both as a consumer of services provided from the outside as well as a provider of services that will be consumed by the outside. Companies that make the claim that they’ve “adopted SOA” should have a view that encompasses all of it, regardless of whether their core business is being a service provider or not.
The management continuum
Mark Palmer of Apama continued his series of posts on myths around the EDA/CEP space, with number 3: BAM and BPM are Converging. Mark hit on a subject that I’ve spoken with clients about, however, I don’t believe that I’ve ever posted on it.
Mark’s premise is that it’s not BAM and BPM that are converging, it’s BAM and EDA. Converging probably isn’t the right word here, as it implies that the two will become one, which certainly isn’t the case. That wasn’t Mark’s point, either. His point was that BAM will leverage CEP and EDA. This, I completely agree with.
You can take a view on our solutions like the one below. At higher levels, the concepts we’re dealing with are more business-centric. At lower levels, the concepts are more technology-centric. Another way of looking at it is that at the higher levels, the products involved would be specific to the line of business/vertical we’re dealing with. At the lower levels, the products involved would be more generic, applicable to nearly any vertical. For example, an insurance provider may have things like quoting and underwriting at the top, but at the bottom, we’d have servers, switches, etc. Clearly, the use of servers are not specific to the insurance industry.
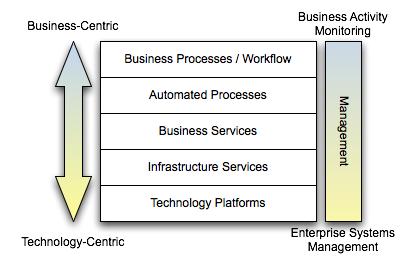
All of these platforms require some form of management and monitoring. At the lowest levels of the diagram, we’re interested in traditional Enterprise Systems Management (ESM). The systems would be getting data on CPU load, memory usage, etc. and technologies like SNMP would be involved. One could certainly argue that these ESM tools are very event-drvien. The collection of metrics and alerts is nearly always done asynchronously. If we move up the stack, we get to business activity monitoring. The interesting thing is that the fundamental architecture of what is needed does not change. Really, the only thing that changes is the semantics of the information that needs to get pushed out. Rather than pushing CPU load, I may be pushing out the number of auto insurance quotes requested and processed. This is where Mark is right on the button. If the underlying systems are pushing out events, whether at a technical level or at a business level, there’s no reason why CEP can’t be applied to that stream to deliver back valuable information to the enterprise, or even better, coming full circle and invoking some automated process to take action.
I think that the most important takeaway on this is that you have to be thinking from an architectural standpoint as you build these things out. This isn’t about running out and buying a BAM tool, a BPM tool, a CEP tool, or anything else. What metrics are important? How will the metrics be collected? How do you want to perform analytics (is static analysis against a centralized store enough, or do you need dynamic analysis in realtime driven by changing business rules)? What do you want to do with the results of that analysis? Establishing a management architecture will help you make the right decisions on what products you need to support it.
The value of events
Joe McKendrick quoted a previous blog entry of mine, but he prefaced my quotes with the statement that I was “questioning the value of EDA to many businesses.” One of things that any speaker/author has to always deal with is the chance that the message we hope comes out doesn’t, and I think this is one of those cases. That being said, if you feel like you are misrepresented, it probably means you didn’t explain it well in first place! So, in the event that others are feeling that I’m questioning the value of EDA, I thought I’d clarify my stance. I am a huge fan of events and EDA. Events can be very powerful, but just as there has been lots of discussions around the difference between SOA and ABOS- a bunch of services, the same holds true for EDA.
The problem does not lie with EDA. EDA, as a concept, has the potential to create value. EDA will fail to produce value, just as SOA will, if it is incorrectly leveraged. Everyone says SOA should begin with the business. Guess what, EDA should as well. While the previous entries I’ve posted and the great comments from the staff at Apama and their postings have called out some verticals where EDA is already being applied successfully, I’m still of the opinion that many businesses would be at significant risk of creating ABOE- a bunch of events. This isn’t a knock on the potential value of events, it’s a knock on the readiness of the business to realize that potential. If the business isn’t thinking of themselves in a service-oriented context, they are unlikely to reach the full potential of SOA. If the business isn’t thinking of themselves in an event-driven context, they are unlikely to reach the full potential of EDA.
Metrics, metrics, metrics
James McGovern threw me a bone in a recent post, and I’m more than happy to take it. In his post, “Why Enterprise Architects need to noodle metrics…” he asks:
Hopefully bloggers such as Robert McIlree, Scott Mark, Todd Biske and others would be willing to share not only successes within their own enterprise when it comes to metrics but also any unintended consequences in terms of collecting them.
I’m a big, big fan of instrumentation. One of the projects that I’m most proud of was when we built a custom application dashboard using JMX infrastructure (when JMX was in its infancy) for a pretty large web-based system. The people that used it really enjoyed the insight it gave them into the run-time operations of the system. I personally didn’t get to use it, as I was rolled onto another project, but the operations staff loved it. Interesting, my first example of metrics being useful comes from that project, but not from the run time management. It came from our automated build system. At the time, we had an independent contractor who was acting as a project management / technical architecture mentor. He would routinely visit the web page for the build management system and record the number of changed files for each build. This was a metric that the system captured for us, but no one paid much attention to it. He started posting graphs showing the number of changed files over time, and how we had spikes before every planned iteration release. He let us know that those spikes disappeared, we weren’t going live. Regardless of the number of defects logged, the significant amount of change before a release was a red flag for risk. This message did two things: first, it kept people from working to a date, and got them to just focus on doing their work at an appropriate pace. Secondly, I do think it helped up release a more stable product. Fewer changes meant more time for integration testing within the iteration.
The second area where metrics have come into play was the initial use of Web Services. I had response time metrics on every single web service request in the system. This became valuable for many reasons. First, because the thing collecting the new metrics was new infrastructure, everyone wanted to blame it when something went wrong. The metrics it collected easily showed that it wasn’t the source of any problem, and actually was a great tool in narrowing where possible problems were. The frustration switched more to the systems that didn’t have these metrics available because they were big, black boxes. Secondly, we caught some rogue systems. A service that typically had 200,000 requests per day showed up on Monday with over 3 million. It turns out a debugging tool had been written by a project team, but that tool itself had a bug and started flooding the system with requests. Nothing broke, but had we not had these metrics and someone looking at them, it eventually would have caused problems. This could have went undetected for weeks. Third, we saw trends. I looked for anything that was out of the norm, regardless of whether any user complained or any failures occurred. When the response time for a service had doubled over the course of two weeks, I asked questions because that shouldn’t happen. This exposed a memory leak that was fixed. When loads that had been stable for months started going up consistently for two weeks, I asked questions. A new marketing effort had been announced, resulting in increased activity for one service consumer. This marketing activity would have eventually resulted in loads that could have caused problems a couple months down the road, but we detected it early. An unintended consequence was a service that showed a 95% failure rate, yet no one was complaining. It turns out a SOAP fault was being used for a non-exceptional situation at the request of the consumer. The consuming app handled it fine, but the data said otherwise. Again, no problems in the system, but it did expose incorrect use of SOAP.
While these metrics may not all be pertinent to the EA, you really only know by looking at them. I’d much rather have an environment where metrics are universally available and the individuals can tailor the reporting and views to information they find pertinent. Humans are good at drawing correlations and detecting anomalies, but you need the data to do so. The collection of these metrics did not have any impact on the overall performance of the system, however, they were architected to ensure that. Metric collection should be performed as an out-of-band operation. As far the practice of EA is concerned, one metric that I’ve seen recommended is watching policy adherence and exception requests. If your rate of exception requests is not going down, you’re probably sitting off in an ivory tower somewhere. Exceptions requests shouldn’t be at zero, either, however, because then no one is pushing the envelope. Strategic change shouldn’t solely come from EA as sometimes the people in the trenches have more visibility into niche areas for improvement. Policy adherence is also needed to determine what policies are important. If there are policies out there that never even come up in a solution review, are they even needed?
The biggest risk I see with extensive instrumentation is not resource consumption. Architecting an instrumentation solution is not terribly difficult. The real risk is in not provided good analytics and reporting capabilities. It’s great to have the data, but if someone has to perform extracts to Excel or write their own SQL and graphing utilities, they can waste a lot of time that should be spent on other things. While access to the raw data lets you do any kind of analysis that you’d like, it can be a time-consuming exercise. It only gets worse when you show it to someone else, and they ask whether you can add this or that.
