Archive for the ‘Information Architecture’ Category
 A Key Challenge of Context Driven Architecture
A Key Challenge of Context Driven Architecture
The idea of context-driven architecture, as coined by Gartner, has been bouncing around my head since the Gartner AADI and EA Summits I attended in June. It’s a catch phrase that basically means that we need to design our applications to take into account as much as possible of the context in which it is executed. It’s especially true for mobile applications, where the whole notion of location awareness has people thinking about new and exciting things, albeit more so in the consumer space than in the enterprise. While I expect to have a number of additional posts on this subject in the future, a recent discussion with a colleague on Data Warehousing inspired this post.
In the data warehousing/business intelligence space, there is certainly a maturity curve to how well an enterprise can leverage the technology. In its most basic form, there’s a clear separation between the OLTP world and the DW/BI world. OLTP handles the day to day stuff, some ETL (extract-transform-load) job gets run to put it into DW, and then some user leverages the BI tools to do analytics or run reports. These tools enable the user to look for trends, clusters, or other data mining type of activities. Now, think of a company like Amazon. Amazon incorporates these trends and clusters into the recommendations it makes for you when you log in. Does Amazon’s back-end run some sophisticated analytics process every time I log in? I’d be surprised if it did, since performing that data mining is an expensive operation. I’m guessing (and it is a guess, I have no idea on the technical details inside of Amazon) that the analytics go on in the background somewhere. If this is the case, then this means that the incorporation of the results of the analytical processing (not the actual analytics itself) is coded into the OLTP application that we use when we log in.
So what does this have to do with context-driven architecture? Well, what I realized is that it all comes down to figuring out what’s important. We can run a BI tool on the DW, get a visual representation, and quickly spot clusters, etc. Humans are good at that. How do you tell a machine to do that, though? We can’t just expect to hook our customer facing applications up to a DW and expect magic to happen. Odds are, we need to take the first step of having a real person look at the information, decide what is relevant or not with the assistance of analytical tools. Only then can we set up some regular jobs to execute those analytics and store the results somewhere that is easily accessible by an OLTP application. In other words, we need to do analysis to figure out what the “right” context is. Once we’ve established the correlation, now we can begin to leverage that context in a way that’s suitable for the typical OLTP application.
So, if you’re like me, and just starting to noodle on this notion, I’d first take a look at your maturity around your data warehousing and business intelligence tools. If you’re relatively mature in that space, that I expect that a leap toward context-driven applications probably won’t be a big stretch for you. If you’re relatively immature, you may want to focus on building that maturity up, rather than jumping into context-driven applications before you’re ready.
Why don’t more IT managers read blogs?
It has been a couple years since I attended a Gartner Summit, and now I’m remembering past experiences. Many of the subjects are presented at a very high level (which is appropriate for the audience at a Gartner conference), and many of the subjects are ones that I’ve spent a lot of time researching on my own. I’ve been trying to attend more sessions this time on subjects that I don’t know much about, so the experience has been better. What I’m wondering, however, is why more of the people attending (and there are easily more than a thousand of them) don’t start reading my blog and that of my colleagues in the industry to pick up this knowledge (in addition to attending conferences like Gartner Summits) and even more importantly, ask questions. Yes, reading my blog doesn’t allow you to travel to some interesting location, but I like to think that the content I provide is appropriate and meaningful.
I hear many questions getting asked over and over at these conferences, and it’s apparent that there’s a very large group out there that simply don’t look for the answers to their questions beyond these conferences. Rather than look for the information, they look for an information source. Guess what folks, this is the information age, and there’s a wealth of it out there. I built up my knowledge not only with research from Gartner, Forrester, Burton Group, ZapThink, and others, but also by reading whitepapers, articles, blogs, and anything I could get my hands on. You can do it as well. Gartner, my blog, conferences, webinars, etc. are all sources of information, and the most important thing is to find information that hits home for you and seems applicable to your environment. If it’s one case study instead of one hundred, it doesn’t matter, as long as it is relevant to your scenario, not someone else’s. Gartner is an excellent source of information, and I like to think that this blog is as well. Use both, and then some, and lets keep things progressing forward so at next year’s Gartner conferences we’re talking about new questions, rather than rehashing the same ones.
Gartner AADI: Information Architecture and BPM
I attended a session from Michael Blechar titled “The Yin & Yang of Processes and Data: Which Will Be King of the Next Generation Applications?” A big title, and as a result, Michael covered a lot of topics. While there wasn’t any new information for me, I would say that this was one of the better big picture overview presented at the conference. Some of the topics he hit on:
- The challenge of multiple metadata systems, and how some of the vendors are approaching it, in particular IBM. He specifically touched on CMDBs (Configuration Management Database), Service Registry/Repository, Software Development Assets, Database Metadata Management, and more. IBM’s approach is to provide a collection of metadata services that reside above all of this systems, providing a federation layer. Hmmm…. this sounds vaguely familiar, I think I called it Master Metadata Management and spoke more on it here.
- The challenges in determining when to use them versus pushing the logic up into a service layer. It discussed the importance of service ownership.
- The importance of information modeling and its importance in SOA.
- The importance of service ownership/stewardship.
- The importance of enterprise architecture operating as a team, and not having silos of business architecture, technology architecture, and information architecture that don’t talk to each other.
Overall, this was probably a good session for many people and hopefully helped them see a bit more of forest for the trees.
Integration at the Desktop
One of my email alerts brought my attention to this article by Rich Seeley, titled “Desktop Integration: The last mile for SOA.” It was a brief discussion with Francis Carden, CEO of OpenSpan Inc. on their OpenSpan Platform. While the article was light on details, I took a glance at their web site, and it seems that the key to the whole thing is this component called the OpenSpan Integrator. Probably the best way to describe it is as a Desktop Service Bus. It can tap into the event bus of the underlying desktop OS. It can communicate with applications that have had capabilities exposed as services via the OpenSpan SOA Module, probably through the OpenSpan Studio interrogation capability. This piqued my interest, because it’s a concept that I thought about many years ago when working on an application that had to exist in a highly integrated desktop environment.
Let’s face it, the state of the art in desktop integration is still the clipboard metaphor. I cut or copy the information I want to share from one application to a clipboard, and then I paste it from the clipboard into the receiving application. In some cases, I may need to do this multiple times, one for each text field. Other “integrated” applications, may have more advanced capabilities, typically a menu or button labeled “Send to ABC…” For a few select things, there are some standard services that are “advertised” by the operating system, such as sending email, although it’s likely that these are backed by operating system APIs put in place at development time. As an example, if I click on a mailto: URL on a web page, that’s picked up by the browser, which executes an API call to the underlying OS capabilities. The web page itself can not publish a message to a bus on the OS that says, “Send an email to user joe@foobar.com with this text.” This is in contrast to a server-side bus where this could be done.
In both the server-side and the desktop, we have the big issue of not knowing ahead of time what services are available and how to represent the messages for interacting with them. While a dynamic lookup mechanism can handle the first half of the problem, the looming problem of constructing suitable messages still exists. This still is a development time activity. Unfortunately, I would argue that the average user is still going to find an inefficient cut and paste approach less daunting than trying to use some of the desktop orchestration tools, such as Apple’s Automator for something like this.
I think the need for better integration at human interaction layer is even more important with the advances in mobile technology. For example, I’ve just started using the new iPhone interface for FaceBook. At present, there is no way for me to take photos from either the Photos application or the Camera application and have them uploaded to FaceBook. If this were a desktop application, it isn’t much better, because the fallback is to launch a file browser and require the user to navigate to the photo. Anyone who’s tried to navigate the iPhoto hierarchy in the file system knows this is far from optimal. It would seem that the right way to approach this would be to have the device advertise Photo Query services that the FaceBook app could use. At the same time, it would be painful for FaceBook if they have to support a different Photo Query service for every mobile phone on the market.
The point of this post is to call some attention to the problem. What’s good for the world of the server side can also be good for the human interaction layer. Standard means of finding available services, standard interfaces for those services, etc. are what will make things better. Yes, there are significant security issues that would need to be tackled, especially when providing integration with web-based applications, but without a standard approach to integration, it’s hard to come up with a good security solution. We need to start thinking about all these devices as information sources, and ensuring that our approach to integration handles not just the server side efforts, but the last mile to the presentation devices as well.
Focus on the consumer
The latest Briefings Direct: SOA Insights podcast is now available. In this episode, we discussed semantic web technologies, among other things. One of my comments in the discussion was that I feel that these technologies have struggled to reach the mainstream because we haven’t figured out a way to make it relevant to the developers working on projects. I used this same argument in the panel discussion at The Open Group EA Practitioners Conference on July 23rd. In thinking about this, I realized that there is a strong connection in this thinking and SOA. Simply put, it is all about the consumer.
Back when my day-to-day responsibilities were programming, I had a strong interest in human-computer interaction and user interface design. The reason for this was that the users were the end consumer of the products I was producing. It never ceased to amaze me how many developers designed user interfaces as if they were the consumer of the application, and wound up giving the real consumer (the end user) a very lousy user experience.
This notion of a consumer-first view needs to be at the heart of everything we do. If you’re an application designer, it doesn’t bode well if you consumer hate using your application. Increasingly, more and more choices for getting things done are freely available on the Internet, and there’s no shortage of business workers that are leveraging these tools, most likely under the radar. If you want your users to use your systems, the best path is make it a pleasant experience for them.
If you’re an enterprise architect, you need to ask who the consumers of your deliverable are? If you create a reference architecture that is only of interest to your fellow enterprise architects, it’s not going to help the organization. If anything, it’s going to create tension between the architecture staff and the developers. Start with the consumer first, and provide material for what they need. A reference architecture should be used by the people coming up with a solution architecture for projects. If your reference architecture is not consumable by that audience, they’ll simply go off and do their own thing.
If you are developing a service, you need to put your effort into making sure it can be easily consumed if you want to achieve broad consumption. It is still more likely today that a project will build both service consumer and service provider. As a result, the likelihood is that the service will only be easily consumable by that first consumer, just as that user interface I mentioned earlier was only easily consumed by the developer that wrote it.
How do we avoid this? Simple: know your consumer. Spend some time on understanding your consumer first, rather than focusing all of your attention on knowing your service. Ultimately, your consumers define what the “right” service is, not you. You can look at any type of product on the market today, and you’ll see that the majority of products that are successful are the ones that are truly consumer friendly. Yes, there are successful products that are able to force their will on consumers due to market share that are not considered consumer friendly, but I’d venture a guess that these do not constitute the majority of successful products.
My advice to my readers is to always ask the question, “who needs to use this, and how can I make it easy for them?” There are many areas of IT that may not be directly involved with project activities. If you don’t make that work relevant to project activities, it will continue to sit off on an island. If you’re in a situation where you’re seen as an expert in some space, like semantic technologies, and the model for using those technologies on project is to have yourself personally involved with those projects, that doesn’t scale. Your efforts will not be successful. Instead, focus on how to make the technology relevant to the problems that your consumers need to solve, and do it in a way that your consumers want to use it, because it makes their life easier.
Acronym Soup
The panel discussion I was involved with at The Open Group Enterprise Architecture Practitioner’s Conference went very well, at least in my opinion. We (myself, our moderator Dana Gardner, Beth Gold-Bernstein, Tony Baer, and Eric Knorr) covered a range of questions on the future of SOA, such as when will we know we’re there, will we still be discussing it 5 years from now or will it be subsumed by EA as a whole, etc.
In our preparations for the panel, one of the topics that was thrown out there was how SOA will play with BPM, EDA, BI, etc. I should point out that our prep call only set the basic framework of what would be discussed, we didn’t script anything. It was quite difficult biting my tongue on the prep call as I wanted to jump right into the debate. Anyway, because it didn’t get the depth of discussion that I was expecting, I thought I’d post some of my thoughts here.
I’ve previously posted on the integration between SOA, BPM, Workflow, and EDA, or probably better stated, services, processes, and events. There are people who will argue that EDA is simply part of SOA, I’m not one of them, but that’s not a debate I’m looking to have here. It’s hard to argue that there are natural connections between services, processes, and events. I just recently posted on BI and SOA. So, it’s time to try to bring all of these together. Let’s start with a picture:
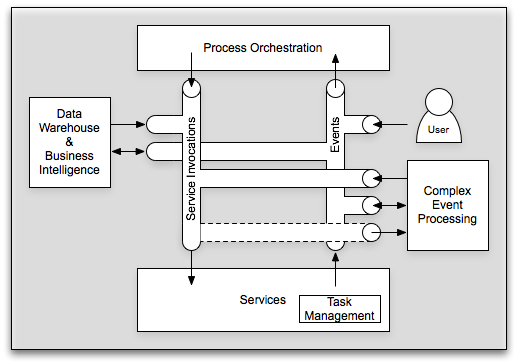
In its simplest form, I still like to begin with the three critical components: processes, services, and events. Services are explicitly invoked by sending a service invocation message. Processes are orchestrated through a sequence of events, whether human-generated or machine generated. Services can return responses, which in essence are a “special” event directed solely at the requestor, or they can publish events available for general listening. So, we’ve covered SOA, BPM, EDA, and workflow. To bring in the world of EDW (Enterprise Data Warehouse), BI (Business Intelligence), CEP (Complex Event Processing), and even BAM (Business Activity Monitoring, although not shown on the diagram), the key is using these messages for purposes other than which they were intended. CEP looks at all messages and is able to provide a mechanism for the creation of new events or service invocations based upon an analysis of the message flow. Likewise, take these same messages and let them flow into your data warehouse and allow your business intelligence to perform some complicated analytics on them. You can almost view CEP as a sort of analytical engine operating on a small window, while business intelligence can act as the analytical engine operating on a large window. Just with CEP, your EDW and BI system can (in addition to report) generate events and/or service invocations. Simply put, all of the technologies associated with all of these acronyms need to come together in a holistic vision. At the conference, Joe Hill from EDS pointed out that when many of these technologies solved 95% of the problem they were brought in for. Unfortunately, when your problem space is broadened to where it all needs to integrate, the laws of multiplication no longer apply. That is, if you have two solutions that solved 95% of their respective problems, they don’t solve 0.95 * 0.95 = 90.25% of the combined problem. Odds are that combined problem falls into the 5% that neither of them solved on their own.
It is the responsibility of enterprise architecture to start taking the broader perspective on these items. The bulk of the projects today are still going to be attacking point problems. While those still need to be solved, we need to ensure that these things fit into a broader context. I’m willing to bet that most service developers have never given thought to whether the service messages could be incorporated into a data warehouse. It’s just as unlikely that they’re publishing events and exposing some potentially useful information for other systems, even where their particular solution didn’t require any events. So, to answer the question of whether SOA will be a term we use 5 years from now, I certainly hope we’re still using it, however, I hope that it’s not still as some standalone initiative distinct from other enterprise-scoped efforts. It all does need to fall under the umbrella of enterprise architecture, but that doesn’t mean that the EA still doesn’t need to be talking about services, events, processes, etc.
Update: I redid the picture to make it clearer (hopefully).
Open Group EA 2007: Rob High
Rob High of IBM is on the stage now with a presentation titled “SOA Foundation” which runs the gamut of topics associated with SOA. One thing he took a lot of time to discuss was the notion of coherency and the importance of semantics to SOA. It was nice to hear some emphasis on this point, as I believe that an understanding of the semantics is a critical component in moving from SOA applied to applications to SOA applied to the enterprise. Just as with the rest of SOA, make sure you understand the semantics first before throwing any semantic technology at it. While there are evolving specs and tools in this space, none of that will do you any good if don’t first understand the semantics themselves and how that information can be leveraged in your project efforts.
