Archive for the ‘Enterprise Architecture’ Category
 My EA Classification
My EA Classification
James asked some of us EA bloggers to try to classify what we do on a daily basis. My breakdown is this, although as I grow in my new job, I would expect this to shift a bit:
- 30% Domain Expert
- 30% Analyst/Strategist
- 30% Technology Expert
- 10% Problem Resolution/Mediation
Note that I used the term “problem resolution/mediation” rather than “troubleshooting.” That was done intentionally to differentiate between troubleshooting operational systems (i.e. production support) versus mediating disagreements between teams, etc. which is far more common for my role. I also added “strategist” after “analyst”, meaning that I’m doing analysis for the purpose of strategic direction. It’s interesting to think about how this will change over time, and the fact that there’s a blurring across these categories. For example, is being an expert in a domain a pre-requisite for being a strategist? It certainly helps, but there are people who simply have a good sense for trends and can easily see where the adoption challenges will typically be, regardless of the domain. I’ll have to make a mental note to revisit this classification a year from now.
Registries, Repositories, and Bears, oh my!
Okay, no bears, sorry. I read post from my good friend Jeff Schneider regarding SAP’s Enterprise Service Repository (ESR). He states:
At the core of the SAP SOA story is the Enterprise Service Repository (ESR). It is actually a combination of both registry and repository. The registry is a UDDI 3.0 implementation and has been tested to integrate with other registries such as Systinet. But the bulk of the work is in their repository. Unlike other commercial repositories, the first thing to notice is that SAP’s is pre-populated (full, not empty). It contains gobs of information on global data types, schemas, wsdl’s and similar artifacts relating to the SAP modules.
This now brings registry/repository into the mix of infrastructure products that SAP customers must make decisions regarding adoption and placement. Do they leverage what SAP provides, or do they go with more neutral products from a pure infrastructure provider such as BEA, HP, SOA Software, or SoftwareAG/WebMethods? The interesting thing with this particular space is that it’s not as simple as picking one. Jeff points out that the SAP ESR comes pre-populated with “gobs of information” on assets from the SAP modules. Choose something else, and this metadata goes away.
I hope that this may bring some much needed attention to the metadata integration/federation space. It’s not just a need to integrate across these competing products, but also a need to integrate with other metadata systems such as configuration management databases and development lifecycle solutions (Maven, Rational, Subversion, etc.). I called this Master Metadata Management in a previous post.
Back when Gartner was pushing the concept of the ESB heavily, I remember an opening keynote from Roy Schulte (I think) at a Web Services Summit in late 2005. He was emphasizing that an organization would have many ESBs that would need to interoperate. At this point, I don’t think that need is as critical as the need for our metadata systems to interoperate. You have to expect that as vendors of more vertical/business solutions start to expose their capabilities as services, they are likely to come with their own registry/repository containing their metadata, especially since there’s no standard way to just include this with a distribution and easily import it into a standalone RR. It would be great to see some pressure from the end-user community to start making some of this happen.
SOA, EA, and EA Frameworks
Both Collin Smith and Rob Eamon responded to my post regarding my participation in an upcoming panel discussion at the Gartner EA Summit asking for my thoughts on SOA, EA, and EA Frameworks, so I thought I’d oblige.
First off, I can be considered a “big SOA” advocate. That is, I think it needs to be applied at something larger than a project scope. I think it needs to be an initiative that is not tied to any one particular implementation project. This implies that it needs to be driven by a group in the organization that is not predominantly consumed with project activities. One obvious candidate, therefore, is an Enterprise Architecture organization. In fact, I can’t think of any other organization that is as good of a fit. Individual managers may embrace it, but they are typically not positioned to guide the organizational and cultural changes required, except at the highest levels. Their primary concern (and rightly so) is typically keeping their stakeholders happy. Enterprise-wide, or even department-wide adoption of SOA can be very disruptive in the short term. So, if I had to pick a group to drive SOA adoption, it will almost always be enterprise architecture.
As for whether “SOA folds into EA,” I agree with Rob’s comments. SOA doesn’t replace Enterprise Architecture, it’s simply one view of the enterprise. Today, one could argue that most organizations view the IT landscape as a collection of applications. Efforts like application rationalization or application portfolio management reinforce this notion. So, you could also say that today we have application oriented architectures. The unit of composition is the application. This isn’t flexible enough, as it is too coarsely defined. If we break these applications into smaller uniits, we now get to service oriented architecture, which I feel is a better way of describing things. Is it the only way? Certainly not. There may be value in a process-oriented view. We still need deployment-centric views that simply show physical, and now virtual, servers. We may need a network-centric view. These are all tools in the toolbox of the Enterprise Architecture team, and depending on your specific responsibilities within that team, some may be more important than others. As I’ve mentioned before, I have a background in human-computer interaction going all the way back to my college days, and one thing that I’ve always believed is that it is very unlikely that one view, whether it be a diagram, a user interface, will meet the needs of everyone. This is why I’m also not a huge fan of EA Frameworks. I think EA frameworks can be of great value when you’re starting out. The scope of EA can be daunting, and if you’re tasked with establishing an EA practice in an organization, it never hurts to begin with an established framework. When those frameworks become too focused on trying to make everything fit into a one-sized fits all approach, rather than on actually making the effort successful is where things can become problematic. Within EA, I don’t think it’s necessarily the fault of the frameworks, but more due to EA being an immature practice. While the concepts have been around for more than a decade, there are still many large organizations (at least in the area where I live) that don’t have an EA practice at all, or have only been doing it for 2 or 3 years. While my sample base is relatively small, my experiences have been that every organization does it differently. Some EA groups have significant authority, some have virtually no authority. Some groups spend all of their time engaged on projects, some have no engagement with projects. Some are committees, some are standing organizations. Some are exclusively focused on managed the technology footprint, some are actively involved with business strategy and business architecture. With this much variation, it’s hard for any framework to achieve wide adoption, because they’re simply not a good fit for the short term needs that the EA team needs to accomplish. When the primary artifact of EA tends to be intellectual capital (i.e. thought leadership, future state models, etc.), you need to have flexibility in how that capital is represented, because consumption is the number one factor, not standardization.
Speaking at Gartner
I’ll be part of two panel discussions at the upcoming Gartner Application Architecture, Development and Integration and Enterprise Architecture Summits. These are being held at the Rio Casino and Conference Center in Las Vegas the week of Dec. 3-7. In the App Arch summit, I’ll be part of a Power Breakfast discussing funding SOA on Tuesday morning at 7:30 am. In the EA summit, I’ll be part of a panel discussion jointly moderated by Gartner and The SOA Consortium discussing the relationship between EA and SOA on Wednesday at 3:30 pm. I’ll be at the two summits from beginning to end (Monday – Friday), so feel free to find me and say hi. One of the more enjoyable parts of these conferences for me is the networking opportunities.
Assume Enterprise!
One of my pet peeves when it comes to discussing services is when an organization gets into debates over whether a particular service is an “enterprise service” or not. These discussions always drive me nuts. My first question usually is what difference does it make? Will you suddenly change the way you construct something? It shouldn’t. More often than not, this conversation comes up when a project team wants to take a shortcut and avoid doing the full analysis that it will take to determine the expected number of consumers, appropriate scoping, etc. Instead, they want to focus exclusively on the project at hand and do only as much as necessary to satisfy that project’s needs. My advice is to always assume that a service is going to be used by the entire enterprise, and if time tells us that it’s only used by one consumer, that’s okay. Unfortunately, it seems that most organizations like to make the opposite assumption: assume that a service will only be used by the particular consumer in mind at that moment unless proven otherwise. This is far easier to swallow in the typical project-based culture of IT today, because odds are the service development team and the service consumer team are most likely the same group all working on the same project.
The natural argument against assuming that all services are “enterprise” services is that all of our services will be horribly over-engineered with a bunch of stuff thrown in because someone said, “What if?” The problem with over-engineering a service (or anything else) doesn’t stem from assuming that a service will have enterprise value, it stems from someone coming up with “what if” scenarios in place of analysis techniques to deeply understand the “right” capabilities that a service needs to provide. Analysis isn’t easy, and there’s no magic bullet that will ensure the right questions are asked to uncover this information, but I think many efforts today are not done to the best of our ability. As a result, people make design decisions based on a best guess, which can lead to either over or under-engineering.
I believe that if you are adopting SOA at an enterprise level, it will result in a fundamental change in the way IT operates and solutions are constructed. Requiring someone to prove that a service is an “enterprise” service before treating it as a service with appropriate processes and hygiene to manage the service lifecycle does nothing to promote this culture change, and in fact, is an inhibitor to that culture change. Will assuming that all services are enterprise services result in higher short term costs? Probably. Building something for use by a broader audience is more expensive, plenty of studies have shown that. On the other hand, assuming that all services are enterprise services will position you far better to achieve cost reduction in the long term as advocated by SOA.
Back in the High Life
Okay, well maybe not the “High Life”, but I’ve had that Steve Winwood song in my head. On Monday, I am returning back to corporate life after nearly a year with MomentumSI. In a nutshell, a year as a consultant has shown me that the corporate world is where I am most comfortable, and best suited for my career goals. MomentumSI treated me very well, and I’m very impressed with their team and their offerings. I learned a lot from the excellent team that they have, and do plan on keeping in touch with them, offering insight from the corporate practitioner’s perspective as they continue their success. I certainly thank Jeff, Alex, Tom, and the rest of the MomentumSI team for the opportunity.
I’m not going to reveal where I’m going, other than to say that it’s a Fortune 500 company in the St. Louis Metro area where I reside, and I’m not returning to A.G. Edwards/Wachovia (AGE isn’t a Fortune 500 company, anyway). I’ll be an enterprise architect, involved with SOA, and other cool architecture topics. While I’m sure people will figure out where I’m working, this blog represents my own personal thoughts and opinions, and not that of my employer or anyone else (and there’s a disclaimer on the right hand side of the blog that states exactly that). I’m very happy that I’m going somewhere that doesn’t mind that I’m a blogger, and I fully intend on adhering to their policies regarding it. So, it’s back to the world of big IT and corporate politics for me, and I’m looking forward to it. While my colleague James McGovern has lamented about the lack of corporate EA bloggers in the past, he can add me back to the list!
Is it about the technology or not?
Courtesy of Nick Gall, this post from Andrew McAfee was brought to my attention. Andrew discusses a phrase which many of us have either heard or used, especially in discussions about SOA: “It’s not about the technology.” He premises that there are two meanings behind this statement:
- “The correct-but-bland meaning is ‘It’s not about the technology alone.’ In other words a piece of technology will not spontaneously or independently start delivering value, generating benefits, and doing precisely what its deployers want it to do.”
- “The other meaning … is ‘The details of this technology can be ignored for the purposes of this discussion.’ If true, this is great news for every generalist, because it means that they don’t need to take time to familiarize themselves with any aspect of the technology in question. They can just treat it as a black box that will convert specified inputs into specified outputs if installed correctly.”
In his post, Nick Gall states that discussions that are operating around the second meaning are “‘aspirational’ — the entire focus is on architectural goals without the slightest consideration of whether such goals are realistically achievable given current technology trends. However, if you try to shift the conversation from aspirations to how to achieve them, then you will inevitably hear the mantra ‘SOA is not about technology.'”
So is SOA about the technology or not? Nick mentions the Yahoo SOA group, of which I’m a member. The list is known for many debates on WS-* versus REST and even some Jini discussions. I don’t normally jump into some of these technology debates not because the technology doesn’t matter, but because I view these as implementation decisions that must be chosen based upon your desired capabilities and the relative priorities of those capabilities. Anne Thomas Manes makes a similar point in her response to these blogs.
As an example, back in 2006, the debate around SOA technology was centered squarely on the ESB. I gave a presentation on the subject of SOA infrastructure at Burton Group’s Catalyst conference that summer which discussed the overlapping product domains for “in the middle” infrastructure, which included ESBs. I specifically crafted my message to get people to think about the capabilities and operational model first, determining what your priorities are, and then go about picking your technology. If your desired capabilities are focused in the run-time operations (as opposed to a development activity like Orchestration) space, and if you developers are heavily involved with the run-time operations of your systems, technologies that are very developer-focused, such as most ESBs, may be your best option. If your developers are removed from run-time operations, you may want a more operations focused tool, such as a WSM or XML appliance product.
This is just one example, but I think it illustrates the message. Clearly, making statements that flat our ignore the technology is fraught with risk. Likewise, going deep on the technology without a clear understanding of the organization’s needs and culture is equally risky. You need to have balance. If your enterprise architects fall into Nick’s “aspirational” category, they need to get off their high horse and work with the engineers that are involved with the technology to understand what things are possible today, and what things aren’t. They need to be involved with the inevitable trade-offs that arise with technology decisions. If you don’t have enterprise architects, and have engineers with deep technical knowledge trying to push technology solutions into the enterprise, they need to be challenged to justify those solutions, beginning with a discussion on the capabilities provided, not on the technology providing them. Only after agreement on the capabilities can we now (and should) enter a discussion on why a particular technology is the right one.
Composite Applications
Brandon Satrom posted some of his thoughts on the need for a composite application framework, or CAF, on his blog and specifically called me out as someone from which he’d like to hear a response. I’ll certainly oblige, as inter-blog conversations are one of the reasons I do this.
Brandon’s posted two excerpts from the document he’s working on, here and here. The first document tries to frame up the need for composition, while the second document goes far deeper into the discussion around what a composite application is in the first place.
I’m not going to focus on the need for composition for one very simple reason. If we look at the definition presented in the second post, as well as articulated by Mike Walker in his followup post, composite applications are ones which leverage functionality from other applications or services. If this is the case, shouldn’t every application we build be a composite application? There are vendors out there who market “Composite Application Builders” which can largely be described as EAI tools focused on the presentation tier. They contain some form of adapter for third party applications, legacy systems, that allow functionality to be accessed from a presentation tier, rather than as a general purpose service enablement tool. Certainly, there are enterprises that have a need for such a tool. My own opinion, however, is that this type of an approach is a tactical band-aid. By jumping to the presentation tier, there’s a risk that these integrations are all done from a tactical perspective, rather than taking a step back and figuring out what services need to be exposed by your existing applications, completely separate from the construction of any particular user-facing application.
So, if you agree with me that all applications will be composite applications, then what we need is not a Composite Application Framework, but a Composition Framework. It’s a subtle difference, but it gets us away from the notion of tactical application integration and toward the strategic notion of composition simply being part of how we build new user-facing systems. When I think about this, I still wind up breaking it into two domains. The first is how to easily allow user-facing applications to easily consume services. Again, in my opinion, there’s not much different here than the things you need to do to make services easily consumable, regardless of whether or not the consumer is user-facing or not. The assumption needs to be that a consumer is likely to be using more than one service, and that they’ll have a need to share some amount of data across those services. If the data is represented differently in those services, we create work for the consumer. The consumer must translate and transform the data from one representation to one or more additional representations. If this is a common pattern for all consumers, this logic will be repeated over and over. If our services all expose their information in a consistent manner, we can minimize the amount of translation and transformation logic in the consumer, and implement it once in the provider. Great concept, but also a very difficult problem. That’s why I use the term consistent, rather than standard. A single messaging schema for all data is a standard, and by definition consistent, but I don’t think I’ll get too many arguments that coming up with that one standard is an extremely difficult, and some might say impossible, task.
Beyond this, what other needs are there that are specific to user-facing consumers? Certainly, there are technology decisions that must be considered. What’s the framework you use for building user-facing systems? Are you leveraging portal technology? Is everything web-based? Are you using AJAX? Flash? Is everything desktop-based using .NET and Windows Presentation Foundation? All of these things have an impact on how your services that are targeted for use by the presentation tier must be exposed, and therefore must be factored into your composition framework. Beyond this, however, it really comes down to an understanding of how applications are going to be used. I discussed this a bit in my Integration at the Desktop posts (here and here). The key question is whether or not you want a framework that facilitates inter-application communication on the desktop, or whether you want to deal with things in a point-to-point manner as they arise. The only way to know is to understand your users, not through a one-time analysis, but through continuous communication, so you can know whether or not a need exists today, and whether or not a need is coming in the near future. Any framework we put in place is largely about building infrastructure. Building infrastructure is not easy. You want to build it in advance of need, but sometimes gauging that need is difficult. Case in point: Lambert St. Louis International Airport has a brand new runway that essentially sits unused. Between the time the project was funded and completed, TWA was purchased by American Airlines, half of the flights in and out were cut, Sept. 11th happened, etc. The needs changed. They have great infrastructure, but no one to use it. Building an extensive composition framework at the presentation tier must factor in the applications that your users currently leverage, the increased use of collaboration and workflow technology, the things that the users do on their own through Excel, web-based tools, and anything else they can find, how their job function is changing according to business needs and goals, and much more.
So, my recommendations in this space would be:
- Start with consistency of data representations. This has benefits for both service-to-service integration, as well as UI-to-service integration.
- Understand the technologies used to build user-facing applications, and ensure that your services are easily consumable by those technologies.
- Understand your users and continually assess the need for a generalized inter-application communication framework. Be sure you know how you’ll go from a standard way of supporting point-to-point communication to a broader communication framework if and when the need becomes concrete.
Is this an “enterprise” service?
A conversation that I’ve seen in many organizations is around the notion of an “enterprise” service. Personally, I think these conversations tend to be a fruitless exercise and are more indicative of a resistance to change. I thought I’d expound on this here and see what others think.
My arguments against trying to distinguish between “enterprise” services and “non-enterprise” services are this:
Classifications are based upon knowledge at hand. Invariably, discussions around this topic always come back to someone saying, “My application is the only one that will use this service.” The correct statement is, “My application is the only one I know of today that will use this service.” The natural followup then is whether or not the team has actually tried to figure out whether anyone else will use that service or not. Odds are they haven’t, because the bulk of projects are still driven from a user-facing application and are constrained from the get-go to only think about what occurs within the boundary of that particular solution. So, in the absence of information that could actually lead to an informed decision, it’s very unlikely that anything will be deemed “enterprise.”
What difference will make? To someone that makes the claim that their service is not enterprise, does it really give them tacit permission to do whatever they want? A theme around SOA is that it approaches things with a “design for change” rather than a “design to last” philosophy. If we follow this philosophy, it shouldn’t matter whether we have one known consumer or ten known consumers. I think that good architecture and design practices should lead to the same solution, regardless of whether something is classified as “enterprise” or “not enterprise.” Does it really make sense to put a service into production without the ability to capture key usage metrics just because we only know of one consumer? I can point to many projects that struggled when a problem occurred because it was a big black box without visibility into what was going on. If there’s no difference in the desired end result, then these classifications only serve to create debate on when someone can bend or break the rules.
What I’ve always recommended is that organizations should assume that all services are enterprise services, and design them as such. If it turns out a service only has one consumer, so what? You won’t incur any rework if only one consumers uses it. The increased visibility through standard management, and the potential cost reductions associated with maintaining consistency across services will provide benefits. If you assume the opposite, and require justification, then you’re at risk of more work than necessary when consumer number two comes along.
It’s certainly true that some analysis of the application portfolio can help create a services blueprint and can lead to a higher degree of confidence in the number of consumers a service might have. This can be an expensive process, however, and projects will still be occurring while the analysis takes place. Ultimately, the only thing that will definitively answer whether a service is “enterprise” or not is time. I’d rather set my organization up for potential success from the very beginning than operate in a reactionary mode when it’s definitive that a service has multiple consumers. What do others think?
Integration at the Desktop, Part 2
In addition to commenting on my blog, Francis Carden, CEO of OpenSpan, also was kind enough to give me a short demo of their product. In my previous post, I introduced the concept of a “Desktop Service Bus” and wondered if the product would behave in this fashion. One of the interesting things I hadn’t thought of, however, is exactly what a desktop service bus should behave like? For that matter, what’s the right model of working with an enterprise service bus? More on that in a second.
Francis did a nice little demonstration for me that showed how custom integrations could be built quickly, first by interrogating existing applications (desktop or web-based) and grabbing possible integration points (virtually any UI element on the screen), and then by using a visual editor to connect up components in a pipeline-like manner. If you’re familiar with server-side application integration technologies, think of this tool as providing an orchestration environment, as well as the ability to build adaptors on the fly through interrogation.
Clearly, this is a step in the right direction. Francis made a great comment to me, which was, “People stopped thinking about this [desktop integration] because they’d long forgotten it was possible.” He’s right about this. With the advent of web-based applications, many people stopped talking about OLE and other desktop application integration techniques. The need hasn’t gone away, however. Again, using the iPhone as an example, many people complain about its lack of cut-and-paste capabilities.
Bringing this back to my concept of a desktop service bus, there clearly is a long way to go. When I see tools like OpenSpan or Apple’s Automator, it’s clear that they’re targeted at when a need to integrate is determined after the fact. You have two systems that no one had thought of integrating previously, but now there is a need to do so. This is no different than integration on the server side, except that you’re much more likely to hear the term “silo” used. When I think about the concept of a desktop service bus, or even an enterprise service bus for that matter, the reason a usage metaphor doesn’t immediately come to mind is that it’s not the way we’ve traditionally done things. When we’re building a new solution, the collection of services available should simply be there. There’s a huge challenge in trying to organize them, but if we can organize all of the classes in the Java API’s and all of the variety of extensions through intelligent code completion, why can’t we do the same with services, whether available through a network interaction or through desktop integration? It will take a while before this becomes the norm, but thankfully, I think the connectivity of the web is actually helping in this regard. Users of sites like Flickr, Facebook, Twitter, MySpace and the like expect the ability to mash and integrate, whether with their mobile phones, their desktop machines, other web sites, and more. Integration as the norm will be a requirement going forward.
Integration at the Desktop
One of my email alerts brought my attention to this article by Rich Seeley, titled “Desktop Integration: The last mile for SOA.” It was a brief discussion with Francis Carden, CEO of OpenSpan Inc. on their OpenSpan Platform. While the article was light on details, I took a glance at their web site, and it seems that the key to the whole thing is this component called the OpenSpan Integrator. Probably the best way to describe it is as a Desktop Service Bus. It can tap into the event bus of the underlying desktop OS. It can communicate with applications that have had capabilities exposed as services via the OpenSpan SOA Module, probably through the OpenSpan Studio interrogation capability. This piqued my interest, because it’s a concept that I thought about many years ago when working on an application that had to exist in a highly integrated desktop environment.
Let’s face it, the state of the art in desktop integration is still the clipboard metaphor. I cut or copy the information I want to share from one application to a clipboard, and then I paste it from the clipboard into the receiving application. In some cases, I may need to do this multiple times, one for each text field. Other “integrated” applications, may have more advanced capabilities, typically a menu or button labeled “Send to ABC…” For a few select things, there are some standard services that are “advertised” by the operating system, such as sending email, although it’s likely that these are backed by operating system APIs put in place at development time. As an example, if I click on a mailto: URL on a web page, that’s picked up by the browser, which executes an API call to the underlying OS capabilities. The web page itself can not publish a message to a bus on the OS that says, “Send an email to user joe@foobar.com with this text.” This is in contrast to a server-side bus where this could be done.
In both the server-side and the desktop, we have the big issue of not knowing ahead of time what services are available and how to represent the messages for interacting with them. While a dynamic lookup mechanism can handle the first half of the problem, the looming problem of constructing suitable messages still exists. This still is a development time activity. Unfortunately, I would argue that the average user is still going to find an inefficient cut and paste approach less daunting than trying to use some of the desktop orchestration tools, such as Apple’s Automator for something like this.
I think the need for better integration at human interaction layer is even more important with the advances in mobile technology. For example, I’ve just started using the new iPhone interface for FaceBook. At present, there is no way for me to take photos from either the Photos application or the Camera application and have them uploaded to FaceBook. If this were a desktop application, it isn’t much better, because the fallback is to launch a file browser and require the user to navigate to the photo. Anyone who’s tried to navigate the iPhoto hierarchy in the file system knows this is far from optimal. It would seem that the right way to approach this would be to have the device advertise Photo Query services that the FaceBook app could use. At the same time, it would be painful for FaceBook if they have to support a different Photo Query service for every mobile phone on the market.
The point of this post is to call some attention to the problem. What’s good for the world of the server side can also be good for the human interaction layer. Standard means of finding available services, standard interfaces for those services, etc. are what will make things better. Yes, there are significant security issues that would need to be tackled, especially when providing integration with web-based applications, but without a standard approach to integration, it’s hard to come up with a good security solution. We need to start thinking about all these devices as information sources, and ensuring that our approach to integration handles not just the server side efforts, but the last mile to the presentation devices as well.
Future of SOA Podcast available
I was a panelist for a discussion on the Future of SOA at The Open Group Enterprise Architecture Practitioner’s Conference in late July. The session was recorded and is now available as a podcast from Dana Gardner’s BriefingsDirect page. Please feel free to followup with me on any questions you may have after listening to it.
Revisiting Service Categories
Chris Haddad of the Burton Group recently had a post entitled, “What is a service?” on their Application Platform Strategies blog. In it, he points out that “it is useful to first categorize services according to the level of interaction purpose.” He goes on to call out the following service categories: Infrastructure, Integration, Primitive (with a sub-category of Data), Business Application, and Composite.
First off, I agree with Chris that categorization can be useful. The immediate question, however, is useful for what? Chris didn’t call this out, and it’s absolutely critical to the success of the categorization. I’ve seen my fair share of unguided categorization efforts that failed to provide anything of lasting value, just a lot of debate that only showed there any many ways to slice and dice something.
As I’ve continued to think about this, I keep coming back to two simple goals that categorizations should address. The first is all about technology, and ensuring that is is used appropriately. Technologies for implementing a service include (but certainly aren’t limited to) Java, C#, BPEL, EII/MDM technologies, EAI technologies, and more. Within those, you also have decisions regarding REST, SOAP, frameworks, XML Schemas, etc. I like to use the term “architecturally significant” when discussing this. While I could have a huge number of categories, the key question is whether or not a particular category is of significance from an architectural standpoint. If the category doesn’t introduce any new architectural constraints, it’s not providing any value for this goal, and is simply generating unnecessary work.
The second goal is about boundaries and ownership. Just as important as proper technology utilization, and probably even more important as far as SOA is concerned, is establishing appropriate boundaries for the service to guide ownership decisions. A service has its own independent lifecycle from its consumers and the other services on which it depends. If you break down the functional domains of your problem in the wrong way, you can wind up making things far worse by pushing for loose coupling in areas where it isn’t needed, and tightly coupling things that shouldn’t be.
The problem that I see too frequently is that companies try to come up with one categorization that does both. Take the categories mentioned by Chris. One category is data services. My personal opinion is this is a technology category. Things falling into this category point toward the EII/MDM space. It doesn’t really help much in the ownership domain. He also mentions infrastructure services and business application services. I’d argue that these are about ownership rather than technology. There’s nothing saying that my infrastructure service can’t use Java, BPEL, or any other technology, so it’s clearly not providing guidance for technology selection. The same holds true for business application services.
When performing categorization, it’s human nature to try to pigeonhole things into one box. If you can’t do that, odds are you’re trying to do too much with your categories. Decisions on whether something is a business service or an infrastructure service are important for ownership. Decisions on whether something is an orchestration service or a primitive service are important for technology selection. These are two separate decisions that must be made by the solution architect, and as a result, should have separate categorizations that help guide those decisions to the appropriate answer.
Acronym Soup
The panel discussion I was involved with at The Open Group Enterprise Architecture Practitioner’s Conference went very well, at least in my opinion. We (myself, our moderator Dana Gardner, Beth Gold-Bernstein, Tony Baer, and Eric Knorr) covered a range of questions on the future of SOA, such as when will we know we’re there, will we still be discussing it 5 years from now or will it be subsumed by EA as a whole, etc.
In our preparations for the panel, one of the topics that was thrown out there was how SOA will play with BPM, EDA, BI, etc. I should point out that our prep call only set the basic framework of what would be discussed, we didn’t script anything. It was quite difficult biting my tongue on the prep call as I wanted to jump right into the debate. Anyway, because it didn’t get the depth of discussion that I was expecting, I thought I’d post some of my thoughts here.
I’ve previously posted on the integration between SOA, BPM, Workflow, and EDA, or probably better stated, services, processes, and events. There are people who will argue that EDA is simply part of SOA, I’m not one of them, but that’s not a debate I’m looking to have here. It’s hard to argue that there are natural connections between services, processes, and events. I just recently posted on BI and SOA. So, it’s time to try to bring all of these together. Let’s start with a picture:
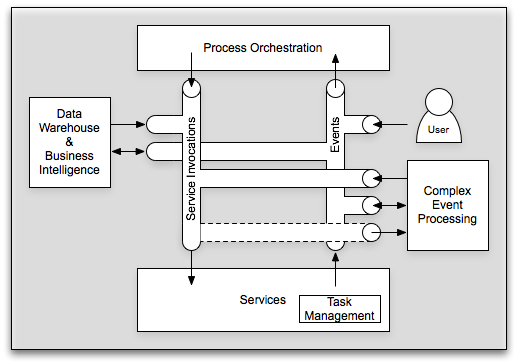
In its simplest form, I still like to begin with the three critical components: processes, services, and events. Services are explicitly invoked by sending a service invocation message. Processes are orchestrated through a sequence of events, whether human-generated or machine generated. Services can return responses, which in essence are a “special” event directed solely at the requestor, or they can publish events available for general listening. So, we’ve covered SOA, BPM, EDA, and workflow. To bring in the world of EDW (Enterprise Data Warehouse), BI (Business Intelligence), CEP (Complex Event Processing), and even BAM (Business Activity Monitoring, although not shown on the diagram), the key is using these messages for purposes other than which they were intended. CEP looks at all messages and is able to provide a mechanism for the creation of new events or service invocations based upon an analysis of the message flow. Likewise, take these same messages and let them flow into your data warehouse and allow your business intelligence to perform some complicated analytics on them. You can almost view CEP as a sort of analytical engine operating on a small window, while business intelligence can act as the analytical engine operating on a large window. Just with CEP, your EDW and BI system can (in addition to report) generate events and/or service invocations. Simply put, all of the technologies associated with all of these acronyms need to come together in a holistic vision. At the conference, Joe Hill from EDS pointed out that when many of these technologies solved 95% of the problem they were brought in for. Unfortunately, when your problem space is broadened to where it all needs to integrate, the laws of multiplication no longer apply. That is, if you have two solutions that solved 95% of their respective problems, they don’t solve 0.95 * 0.95 = 90.25% of the combined problem. Odds are that combined problem falls into the 5% that neither of them solved on their own.
It is the responsibility of enterprise architecture to start taking the broader perspective on these items. The bulk of the projects today are still going to be attacking point problems. While those still need to be solved, we need to ensure that these things fit into a broader context. I’m willing to bet that most service developers have never given thought to whether the service messages could be incorporated into a data warehouse. It’s just as unlikely that they’re publishing events and exposing some potentially useful information for other systems, even where their particular solution didn’t require any events. So, to answer the question of whether SOA will be a term we use 5 years from now, I certainly hope we’re still using it, however, I hope that it’s not still as some standalone initiative distinct from other enterprise-scoped efforts. It all does need to fall under the umbrella of enterprise architecture, but that doesn’t mean that the EA still doesn’t need to be talking about services, events, processes, etc.
Update: I redid the picture to make it clearer (hopefully).
Open Group EA 2007: Andres Carvallo
Andres Carvallo is the CIO for Austin Energy. He was just speaking on how the Internet has changed the power industry. He brought up the point that we’ve all experienced, where we must call our local power company to tell them that the power is out. Take this in contrast to the things you can do with package delivery via the Internet, and it shows how the Internet age is changing customer expectations. While he didn’t go into this, my first reaction to this was that IT is much like the power company. It’s all too often that we only know a system is down because an end user has told us so.
This leads to discussion of something that is all too frequently overlooked, which is the management of our solutions. Visibility into what’s going on is all too often an afterthought. If you exclusively focus on outages, you’re missing the point. Yes, we do want to know when the .001% of downtime occurs. What makes things more important, however, is an understanding of what’s going on the other 99.999% of the time. It’s better to refer this as visibility rather than monitoring, because monitoring leads to narrow thinking around outages, rather than on the broader information set.
Keeping with the theme of the power industry, clearly, Austin Energy needs to deal with the varying demands of the consumers of their product. That may range from some of the major technology players in the Austin area versus your typical residential customer. Certainly, all consumers are not created equal. Think about the management infrastructure that must be in place to understand these different consumers. Do you have the same level of management in your IT solutions to understand different consumers of your services?
This is a very interesting discussion, especially given today’s context of HP’s acquisition of Opsware (InfoWorld report, commentary/analysis from Dana Gardner and Tony Baer).
